Teleoscope
Teleoscope is a system for exploring large document sets by building machine learning workflows. Teleoscope (from teleology (opens in a new tab) and telescope (opens in a new tab)) helps to discover purpose and meaning. The system is designed with qualitative researchers in mind, but can be used by anyone interested in exploring themes (opens in a new tab) in a large dataset.
See how it works
Overview diagram
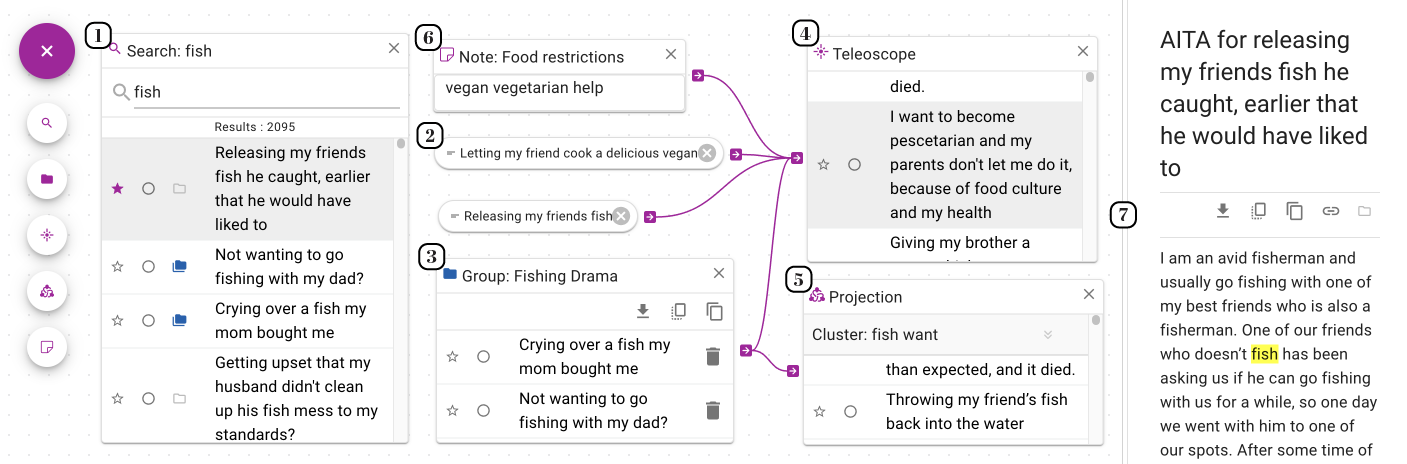 (1) Start by performing a standard keyword search to explore documents;
(2) Drag documents onto the workspace;
(3) Group documents for organization;
(4) Teleoscopes can use documents, notes or groups as control inputs;
(5) Projections create clusters using groups as control inputs;
(6) Notes can contain arbitrary text which is also vectorized and can be used as a control input to a Teleoscope;
(7) Read documents on the sidebar as well as edit your saved items, bookmarks, and settings. Keyboard navigation through document lists and bookmarking are included for quick exploration and group creation.
(1) Start by performing a standard keyword search to explore documents;
(2) Drag documents onto the workspace;
(3) Group documents for organization;
(4) Teleoscopes can use documents, notes or groups as control inputs;
(5) Projections create clusters using groups as control inputs;
(6) Notes can contain arbitrary text which is also vectorized and can be used as a control input to a Teleoscope;
(7) Read documents on the sidebar as well as edit your saved items, bookmarks, and settings. Keyboard navigation through document lists and bookmarking are included for quick exploration and group creation.
You can see how Teleoscope works by mixing the semantics of your control input examples. Above, we have the concept of fish mixed with the concept of vegetarianism. In the Teleoscope output, you can see that it has found documents that have to do with pescatarianism, which is a dietary choice that is like vegetarianism but you can also eat fish (opens in a new tab). Nowhere in the text does it mention vegetarianism, yet it is highly ranked in the Teleoscope output.
Video guide
Tutorial
This tutorial uses data from Reddit's AmITheAsshole (opens in a new tab) advice forum. Follow along step-by-step to learn how the Teleoscope system works and to explore this fascinating slice of the internet.
Search
A Teleoscope workflow starts with a normal text search.
You can use spaces for multiple search terms, quotes to search for exact phrases,
and a minus sign to exclude words. The searches are case-insensitive and fuzzy,
which means that suffixes such as -ing are ignored.
Try copying the following search and clicking on a post to read it.
"friendly" wedding -motherUse up ⬆️ or down ⬇️ to navigate the search results and Enter to
bookmark.
Bookmarks
You can choose documents that you'd like to save to read later by bookmarking them.
Bookmarks are one of a few ways to group documents together.
Try bookmarking by clicking on the ⭐ or by pressing Enter while a document is selected.
You can click the to make a group from the existing bookmarks.
Groups
You can create groups of documents. At first, you can use this just to organize your documents. But, as you use the Teleoscope system more, you'll start to use groups as a primary interaction mechanism.
Workspace
All operations take place on the Workspace. You can:
- Pan by clicking and dragging on the background
- Move by clicking and dragging on a workspace item's titlebar
- Resize by clicking and dragging on the edge of a workspace item ↕️ ↔️
- Drag and drop by clicking on a document in the group and dragging it outside of the group
- Zoom in and out by scrolling the mouse wheel
There are also reset controls on the left and a minimap on the right if you get lost.
Teleoscoping
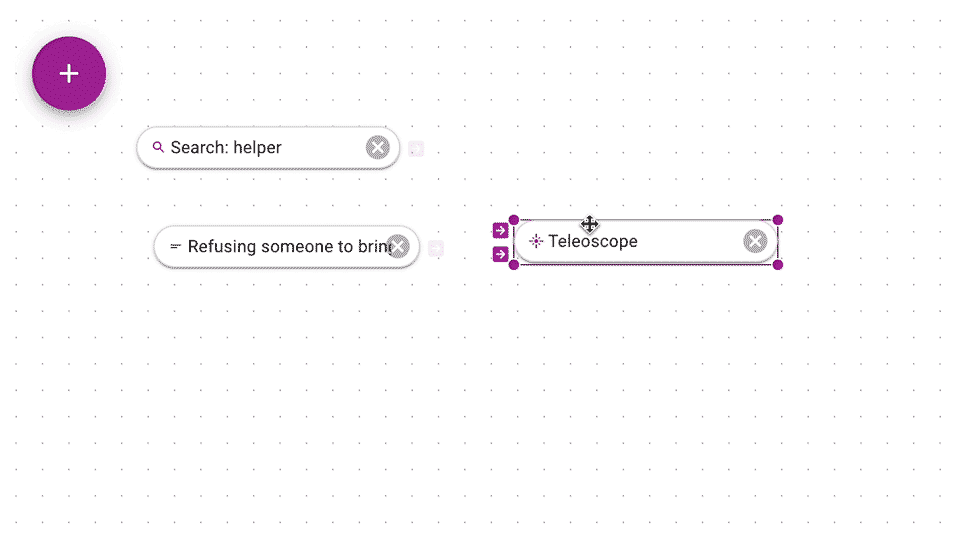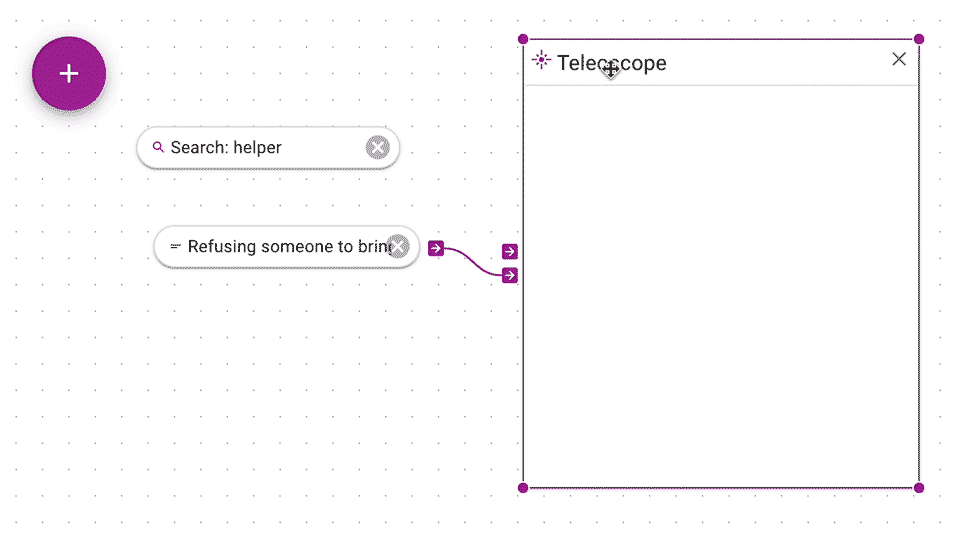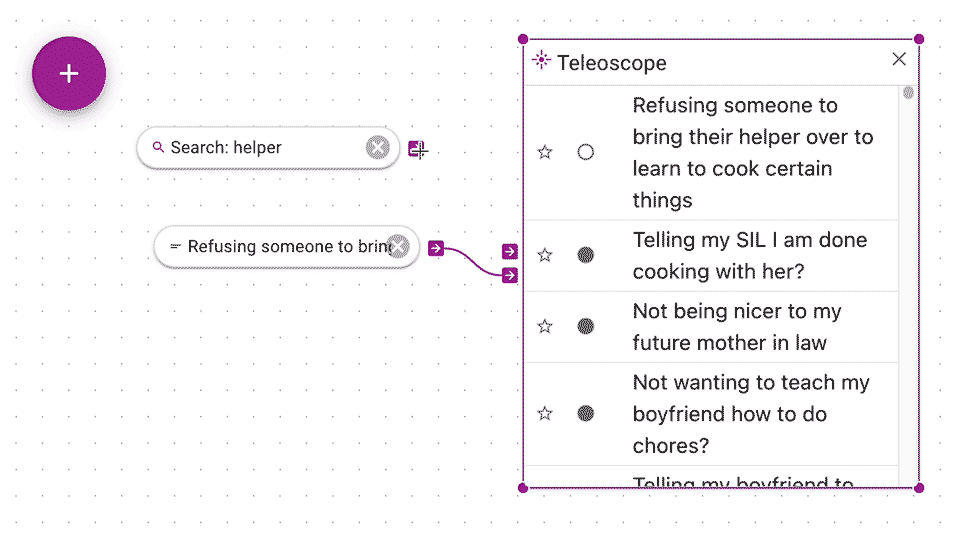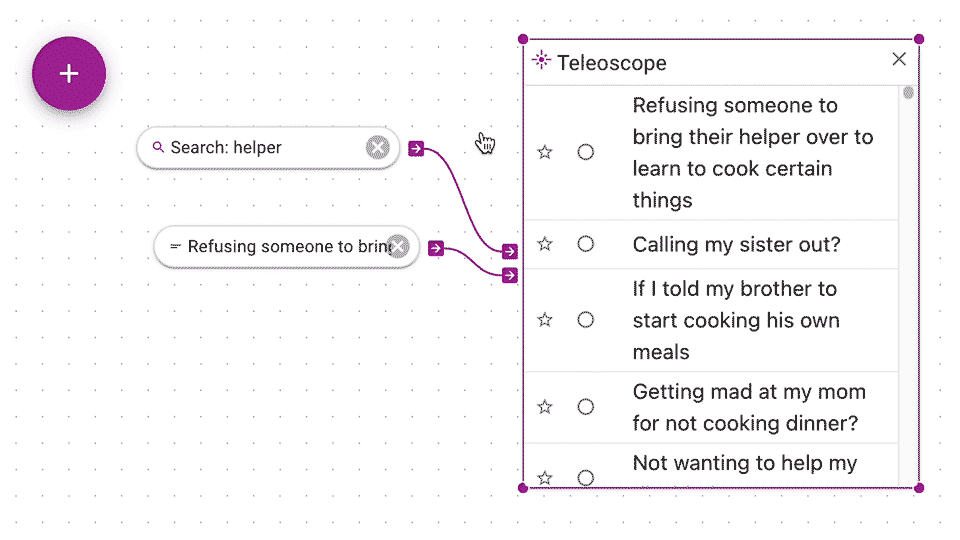
Keyword searches, like above, are great, but they don't get you documents that are conceptually similar but have different keywords. With Teleoscope, you search by example. The big idea with the Teleoscope that we mix your example documents together to get a much more interesting and relevant results. You connect examples of documents (or groups) to the Teleoscope.
You can click and drag from output arrow of a document or group to the bottom control input arrow of a Teleoscope. Think of mixing together examples like mixing together paints. The Teleoscope produces a list of documents that are closest in concept (and math) to your example documents.
You can also restrict the Teleoscope to only rank from within a particular source such as a search or group by connecting to the top source input.
Projections
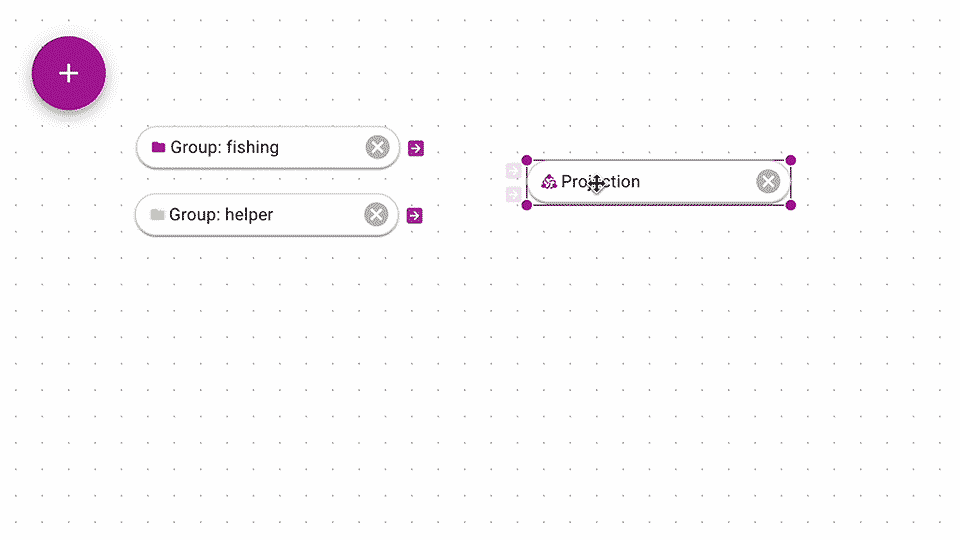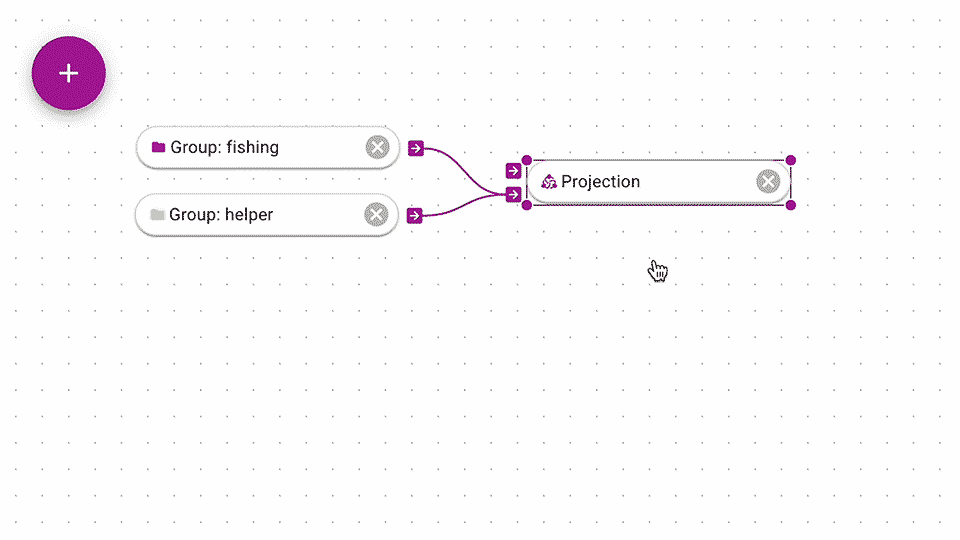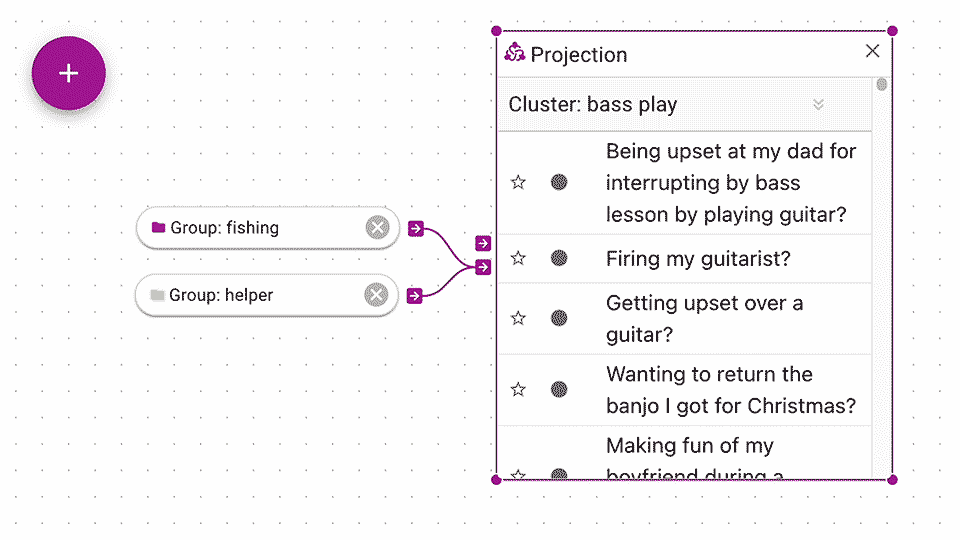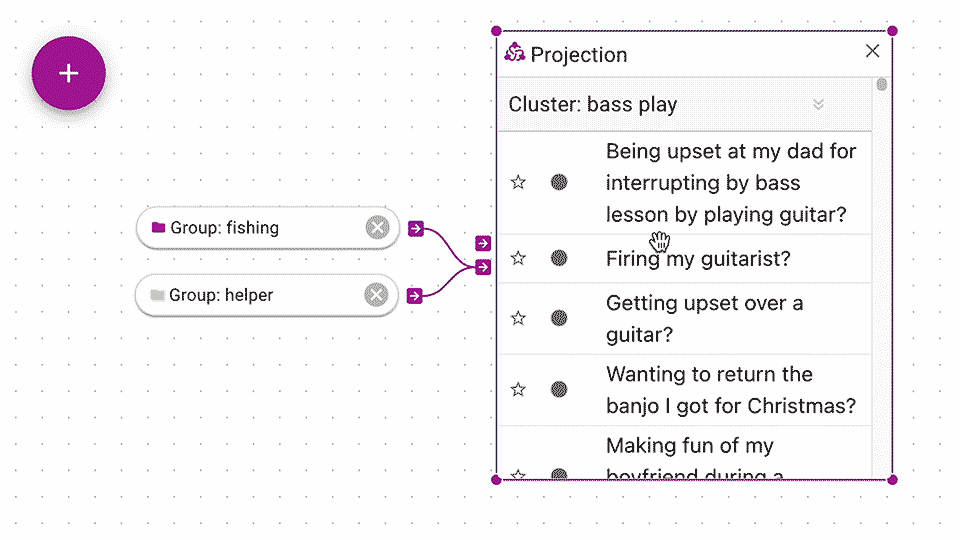
At some point, you might want groups to be automatically created for you.
Similar to the Teleoscope function, you can use a Projection to automatically create clusters for you.
Notes
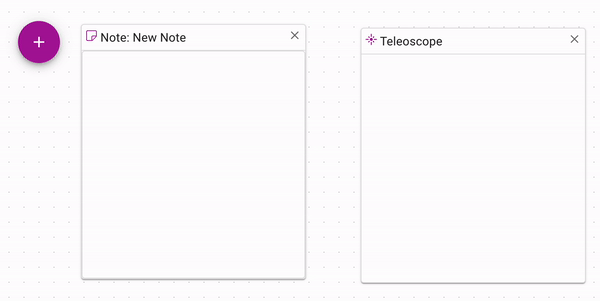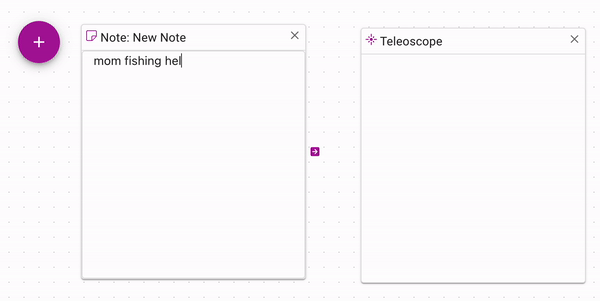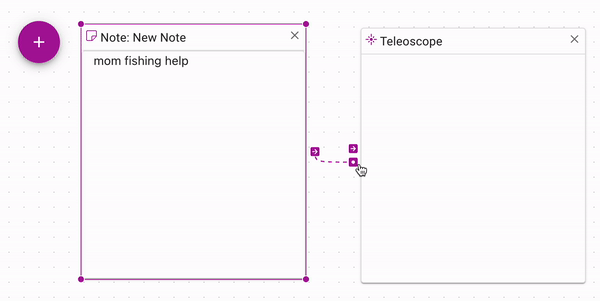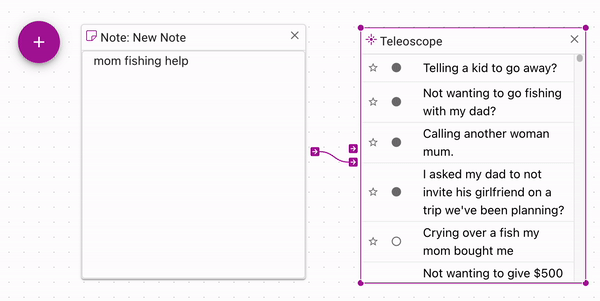
You can write notes for yourself just to keep notes. However, note contents are vectorized.
This means that you can use them as controls for Teleoscopes.
Concepts
Teleoscope is supported by a variety of computational systems. At its core, Teleoscope is a distributed (opens in a new tab), cloud-first (opens in a new tab), machine-learning (opens in a new tab) workflow editor that uses prebuilt language models and algorithms to perform semi-supervised (opens in a new tab) topic modelling (opens in a new tab). But that's a lot of buzzwords. In this section, we'll go over the core concepts and design choices for Teleoscope.
Document representation
Document similarity is basically a measure of how many words, phrases, and sentences overlap between two documents. For example, a bag-of-words (opens in a new tab) model might use the following process to produce a similarity score:
sentence_1 = "The dog walked to the park."
sentence_2 = "The dog chewed on a bone."
sentence_3 = "The dog napped in the park."Getting rid of common words and word endings (stemming (opens in a new tab)), the sentences would be turned into:
sentence_1 = "dog walk park"
sentence_2 = "dog chew bone"
sentence_3 = "dog nap park"If we count the overlapping words, sentence 1 and sentence 3 are the most similar.
That should make intuitive sense: they both have "dog" and "park" in them. If we wanted
to use a vector representation to check similarity, we would create a vector where each
entry mapped to a single word. We will put a 1 in the vector if the word exists in the
sentence, and a 0 otherwise.
vector = < dog walk park chew bone nap >
sentence_1 = < 1 1 1 0 0 0 >
sentence_2 = < 1 0 0 1 1 0 >
sentence_3 = < 1 0 1 0 0 1 >This simple example is only to build some intuition for how a document can be represented by a vector. We might want a model that "knows" that "cat" and "dog" are conceptually similar words. In Teleoscope, we use a pre-built model called the Universal Sentence Encoder (opens in a new tab) which allows for more complex semantic similarity to be captured. The USE model is good for capturing categorical similarities because it was trained on huge amounts of data.
There is a core design trade-off between using a pre-built model vs. building a model off of the dataset that you're interested in studying. If you build your own model, you will create similarity scores based on how often words show up together in your own dataset. However, for words that most people would consider to be similar, you might not have enough data to create good similarity scores. For example, we might have a dataset where "dog" and "cat" do not appear very often near each other, or along with other conceptually similar words like "pet" or "fur".
By starting with a model that has been trained on large amounts of data, we can capture semantics that a smaller model may not be able to. However, then we have the problem of determining similarities that might be present in our dataset, or in our minds, which may not be captured by the USE model. However, Teleoscope is model-agnostic. If you wanted to create a version of Teleoscope with a different model, it would be quite easy to do.
The Teleoscope Ranking Tool
The eponymous Teleoscope tool ranks documents by similarity using the USE model.
When multiple documents are input as controls, the Teleoscope will average the
document vectors to give you a "mix" of the different vectors. In this way, a
Teleoscope search is a search by example. You can connect many documents to
tune the Teleoscope rank to follow conceptual similarities that you imagine.
You can also vectorize your own sentences by creating a note and add it into the mix.
In this way, you are building up a visual trace of a concept that you're exploring. You can capture your own thought process by seeing which documents are feeding into the Teleoscope, and what you had to do to come up with the machine representation you were interested in.
Grouping and Projections
Grouping means that you've decided that certain documents are thematically similar whether or not the machine has. Of course, this can just be an organizational tool, but you can also use groups as inputs to Teleoscopes and Projections. This is where the power of the system can really be seen.
A Projection produces groups of documents that the machine has clustered together as similar based on the groups you use as control inputs. It is called a projection because it performs dimensionality reduction (opens in a new tab) on the document vectors. Think "projection" like "projecting your shadow onto a wall." It's taking something higher-dimensional and creating a lower-dimensional representation of it. Teleoscope uses the UMAP (opens in a new tab) library to perform our projections and HDBSCAN (opens in a new tab) to perform our clustering.
The practical upshot is that our system will attempt to cluster the document source based on the groups you provide. You can think of it like pruning a large, general language model like USE for your specific way of thinking about your document set.
Boolean Operations
Boolean (opens in a new tab) operations are functions that operate on sets of things (opens in a new tab). You can think of them as ways to join or filter document sources. They can be chained together to create more complex joins and filters. And you can use them as sources or controls for Teleoscopes and Projections.
Union
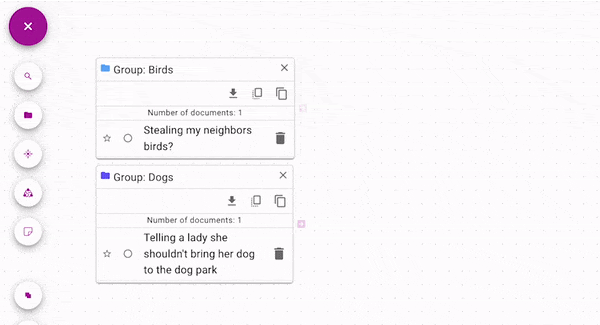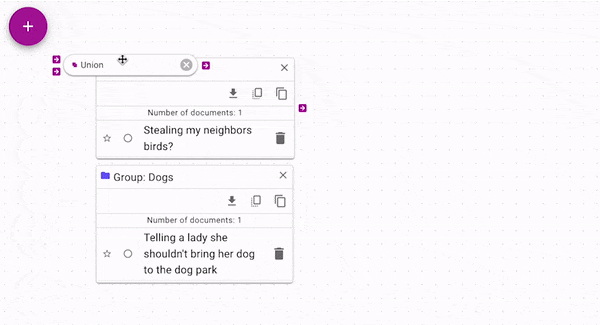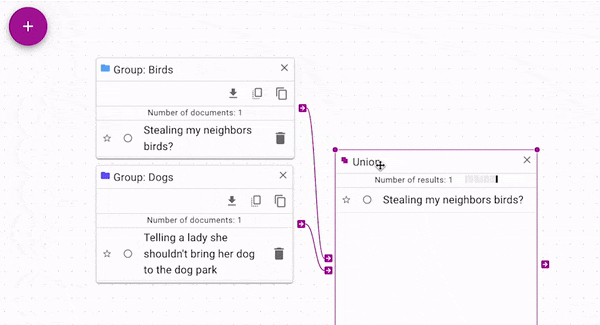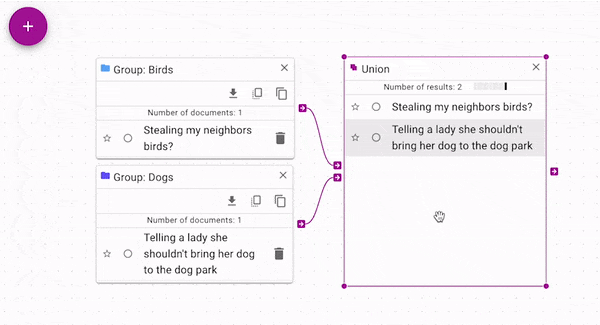 Union (opens in a new tab) joins each source with all of
the control documents. You can use it to join groups, searches, or single documents without
merging the groups by hand. In the above figure, notice how each group alone has a single document.
Both documents are present in the union's output.
Union (opens in a new tab) joins each source with all of
the control documents. You can use it to join groups, searches, or single documents without
merging the groups by hand. In the above figure, notice how each group alone has a single document.
Both documents are present in the union's output.
Difference
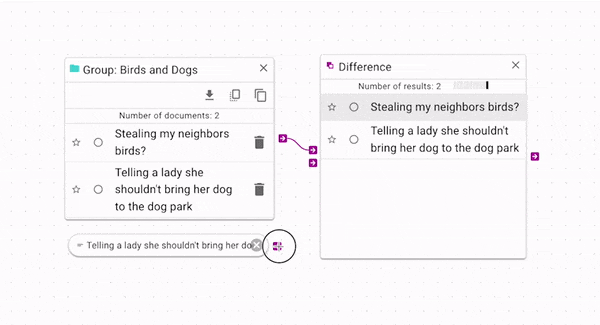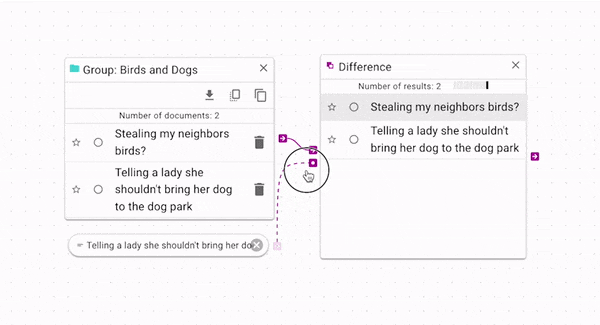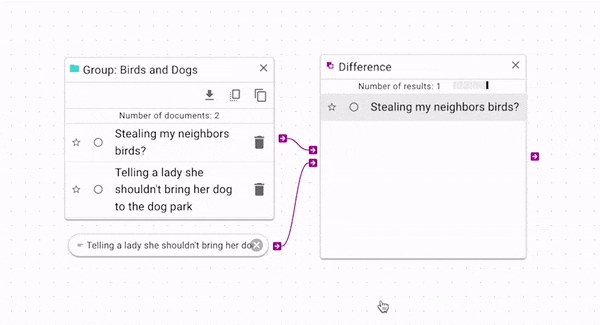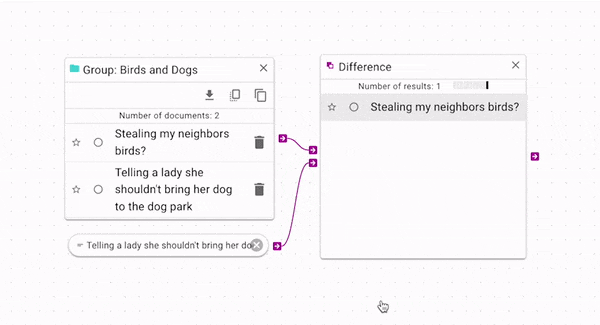 Difference (opens in a new tab) subtracts
the control documents from the source. You can use it to filter out documents from a source.
In the above example, the original group has two documents. One of the documents is being used
to filter itself out of the group. This is a simple example for explanatory purposes; a more
complex example is shown below in the Example Workflow Patterns section.
Difference (opens in a new tab) subtracts
the control documents from the source. You can use it to filter out documents from a source.
In the above example, the original group has two documents. One of the documents is being used
to filter itself out of the group. This is a simple example for explanatory purposes; a more
complex example is shown below in the Example Workflow Patterns section.
Intersection
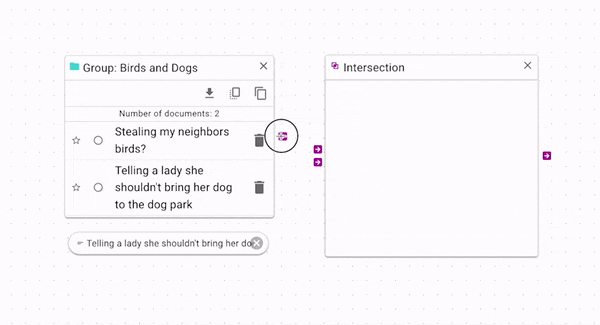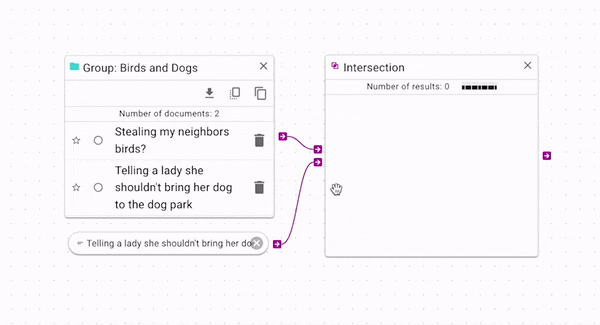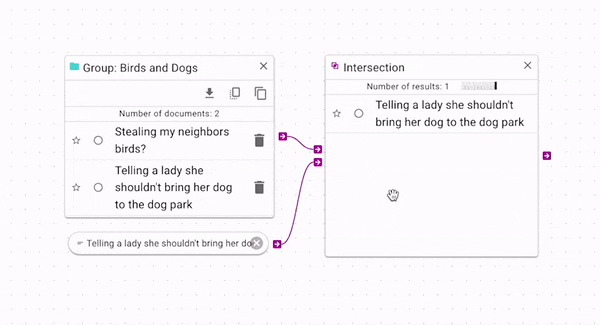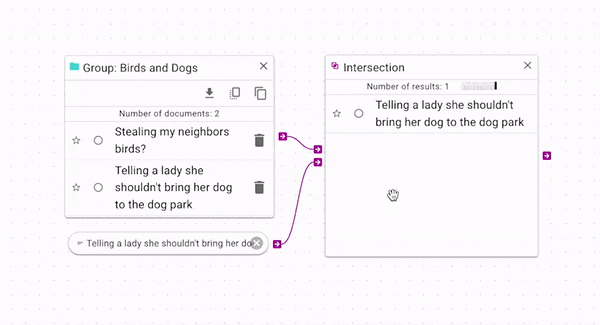 Intersection (opens in a new tab) produces only the documents that are present in both the source and control. You can use it wherever you would like to have more strict criteria for a source. In the above example, you can see that it gives the opposite result of the difference operation: the control document is retained, but the other documents are removed. Again, there is a more complex example in the Example Workflow Patterns section.
Intersection (opens in a new tab) produces only the documents that are present in both the source and control. You can use it wherever you would like to have more strict criteria for a source. In the above example, you can see that it gives the opposite result of the difference operation: the control document is retained, but the other documents are removed. Again, there is a more complex example in the Example Workflow Patterns section.
Exclusion
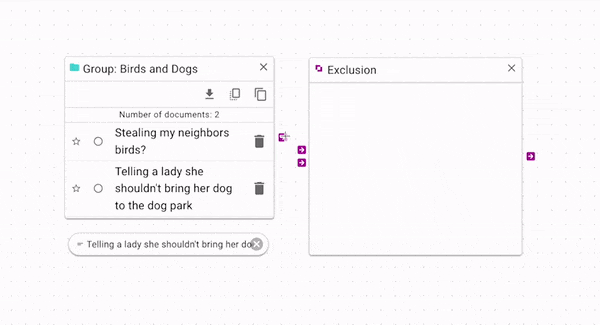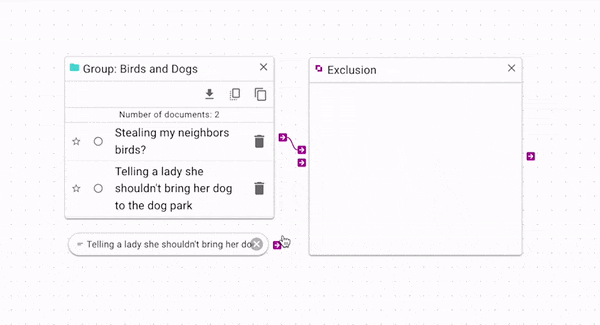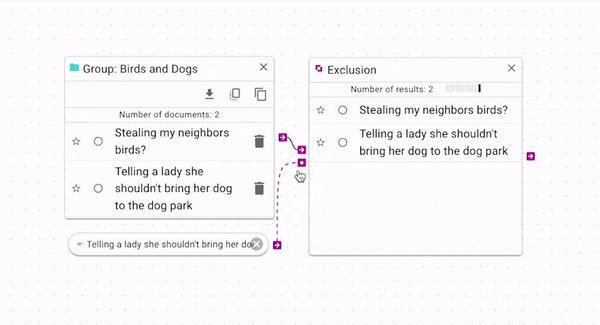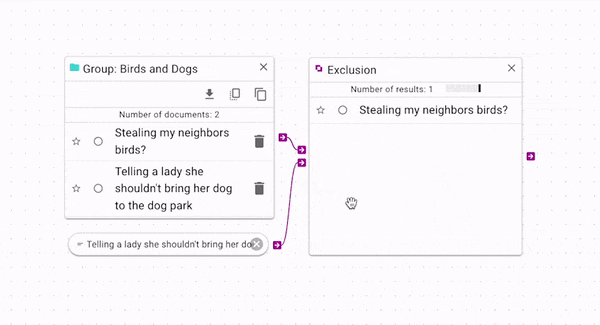 Exclusion (opens in a new tab) produces only the documents that are not in both source and control. You can use this to find which documents are unique to each group. In the above example, we can see that because the control document is in the source group, it is removed from the exclusion output. Again, a more complex example is available in the Example Workflow Patterns section.
Exclusion (opens in a new tab) produces only the documents that are not in both source and control. You can use this to find which documents are unique to each group. In the above example, we can see that because the control document is in the source group, it is removed from the exclusion output. Again, a more complex example is available in the Example Workflow Patterns section.
Example Workflow Patterns
The operations that we provide you are simple and can be chained together to achieve more complex results. Here are some design patterns that you can use if you want to achieve specific outcomes.
Focus on a snippet of text
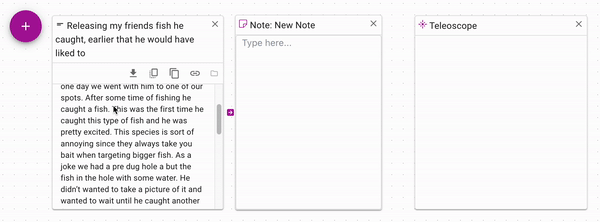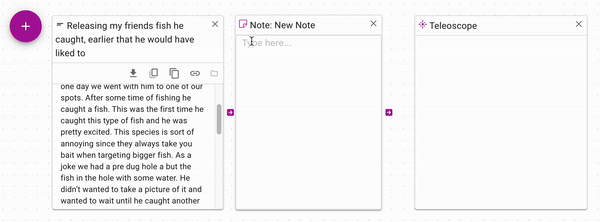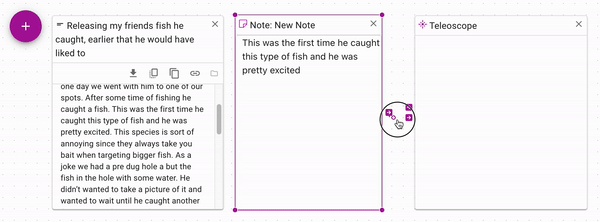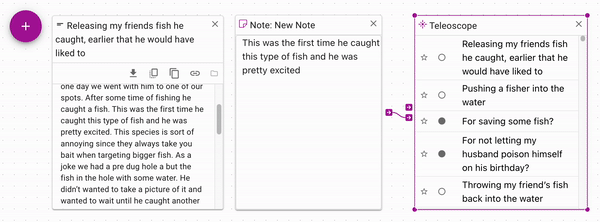 Since notes can have arbitrary text, you can copy and paste a snippet of text
into a note from a document. Connect the note to the control input of a Teleoscope
to only use the snippet of text that you care about.
Since notes can have arbitrary text, you can copy and paste a snippet of text
into a note from a document. Connect the note to the control input of a Teleoscope
to only use the snippet of text that you care about.
Ranking
 The Teleoscope tool ranks documents according to a source document. If you want to sort a source
(search, document, or group) by similarity to another source, you can connect the one you want
to rank to to the top source input, and the other to the bottom control input.
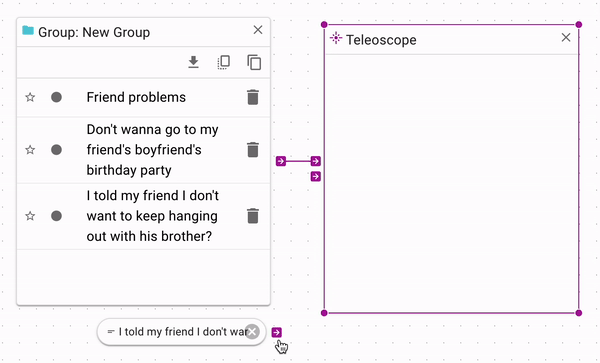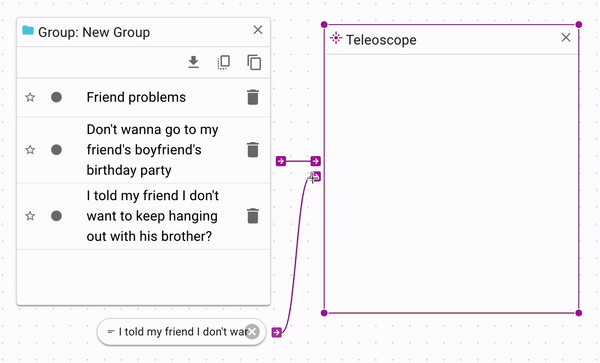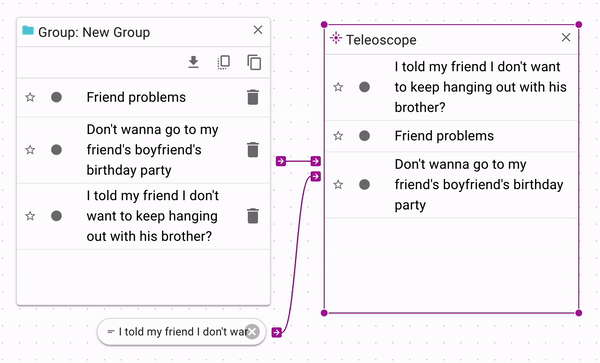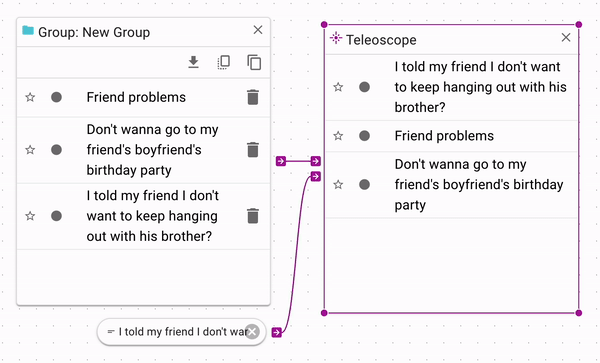
As you can see in this example, the document that the group is being sorted relative to is
now at the top of the list.
The Teleoscope tool ranks documents according to a source document. If you want to sort a source
(search, document, or group) by similarity to another source, you can connect the one you want
to rank to to the top source input, and the other to the bottom control input.
As you can see in this example, the document that the group is being sorted relative to is
now at the top of the list.
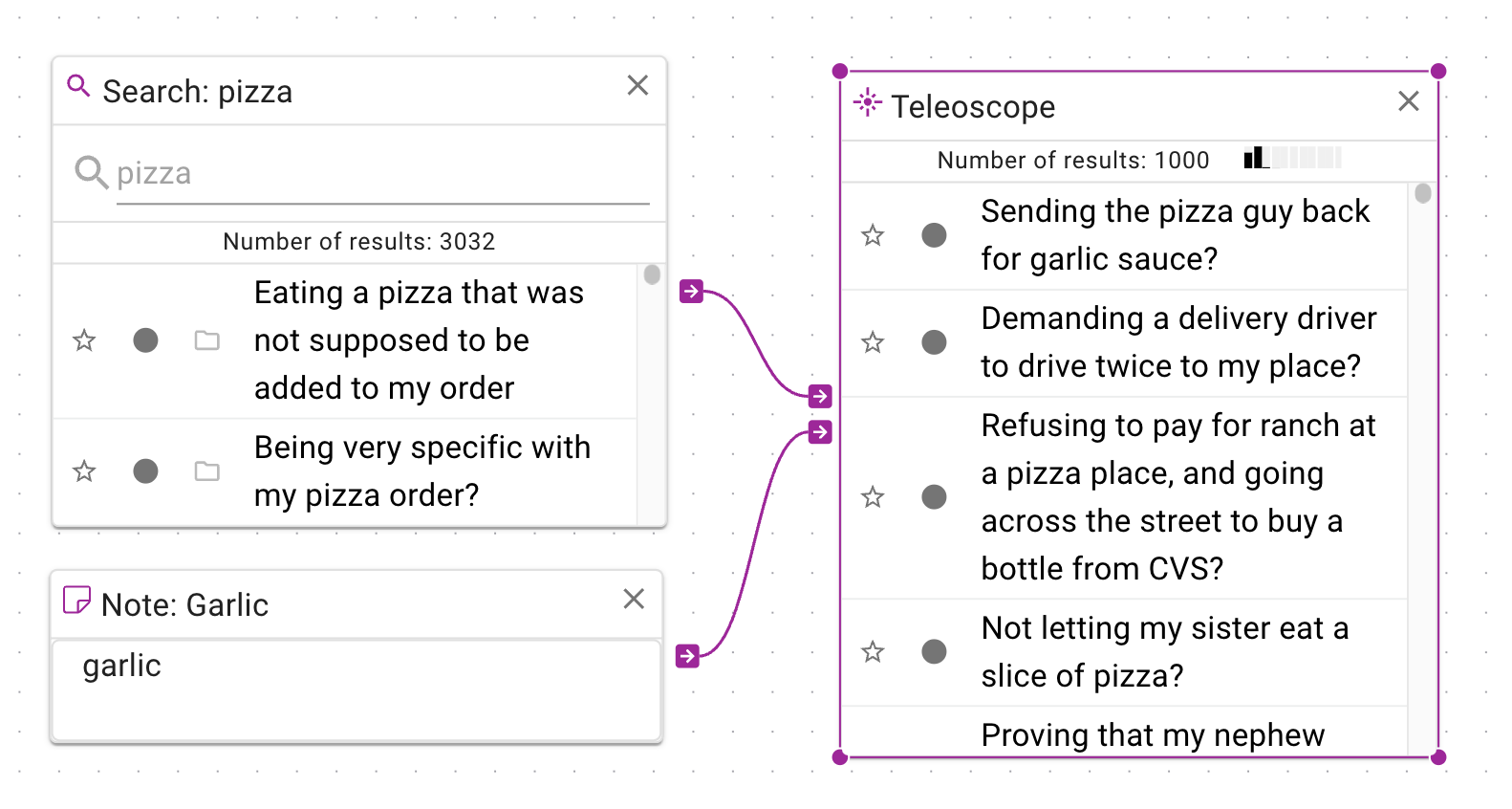
Similarly, here's a pattern where you can rank a search by word. On the left, you can see that the
pizza search is unordered; by adding the Note as a control with the word garlic, the pizza search
is now ordered by documents that are similar to the word garlic.
Filtering a Search
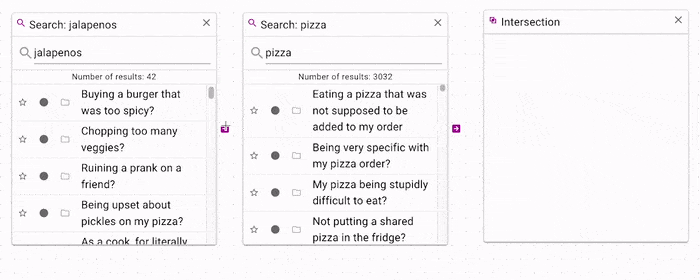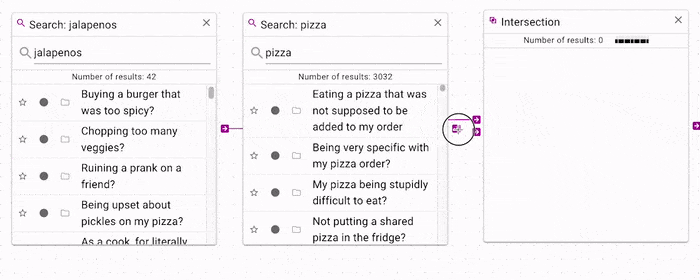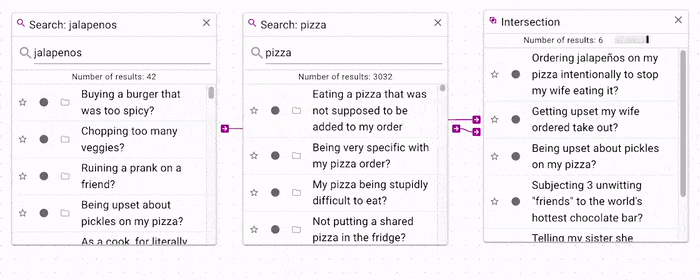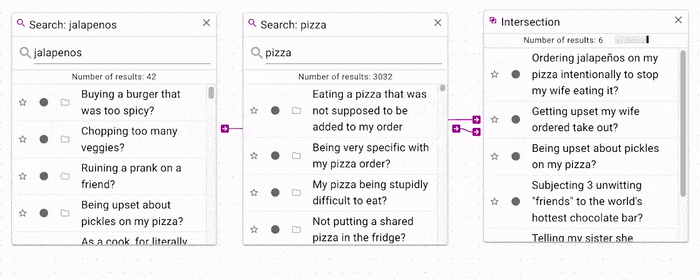 If you want to filter a search by another seach, you can use the intersection operation.
In the above example, the
If you want to filter a search by another seach, you can use the intersection operation.
In the above example, the jalapenos search is filtered by the pizza search, which
produces only documents that contain both jalapenos and pizza.
Chaining boolean operations
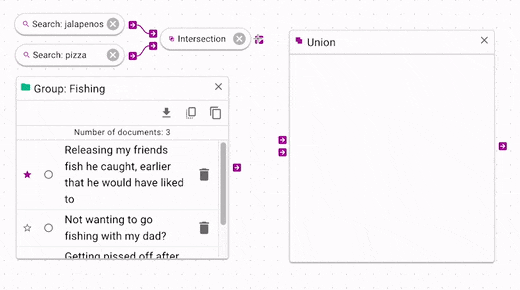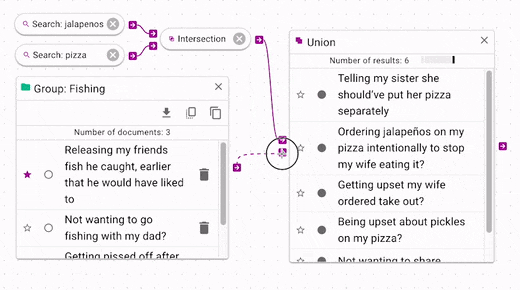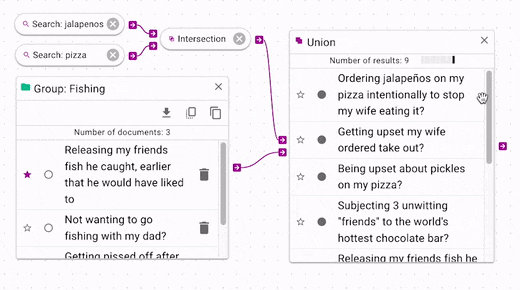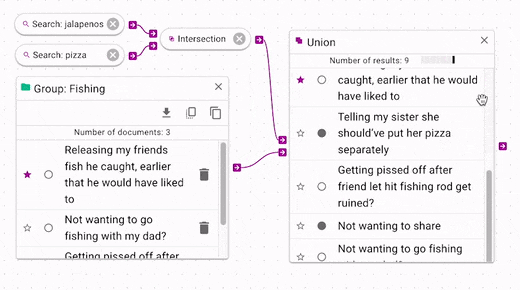 Boolean operations can be chained indefinitely (although chaining more will update more slowly).
In the above example, we see that the intersection is joined with the
Boolean operations can be chained indefinitely (although chaining more will update more slowly).
In the above example, we see that the intersection is joined with the Fishing group by using union.
All of documents that are in Fishing are now joined with the intersection results.
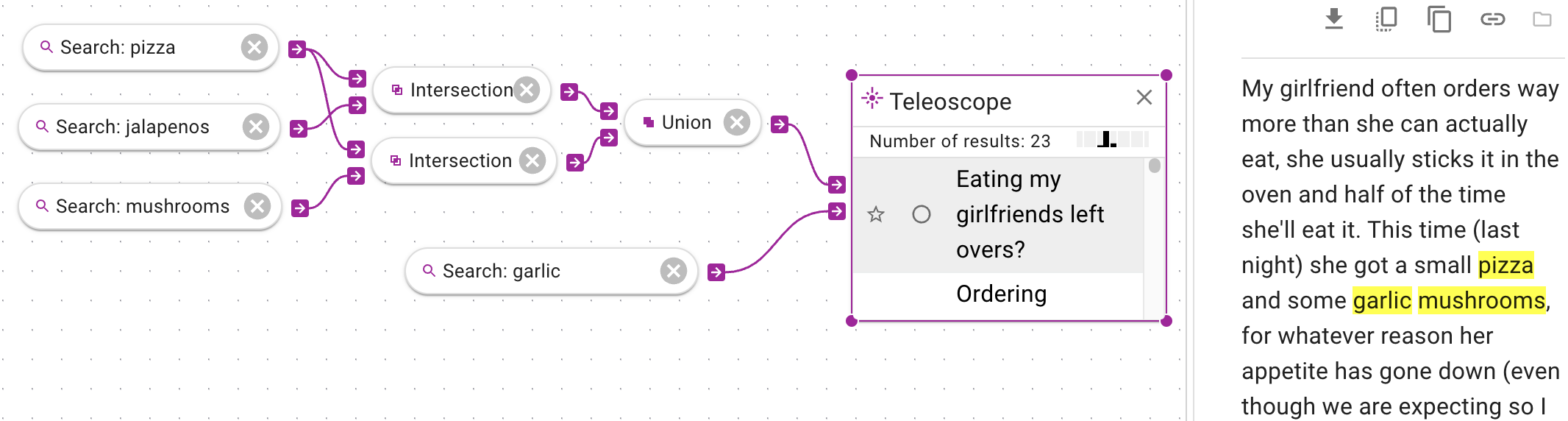
In this example, many operations are chained together to produce a desired outcome.
The first intersection produces only documents that contain both pizza and jalapenos;
the second intersection produces only documents that contain both pizza and mushrooms.
The results are joined together, then ranked with a Teleoscope according to a search for garlic.
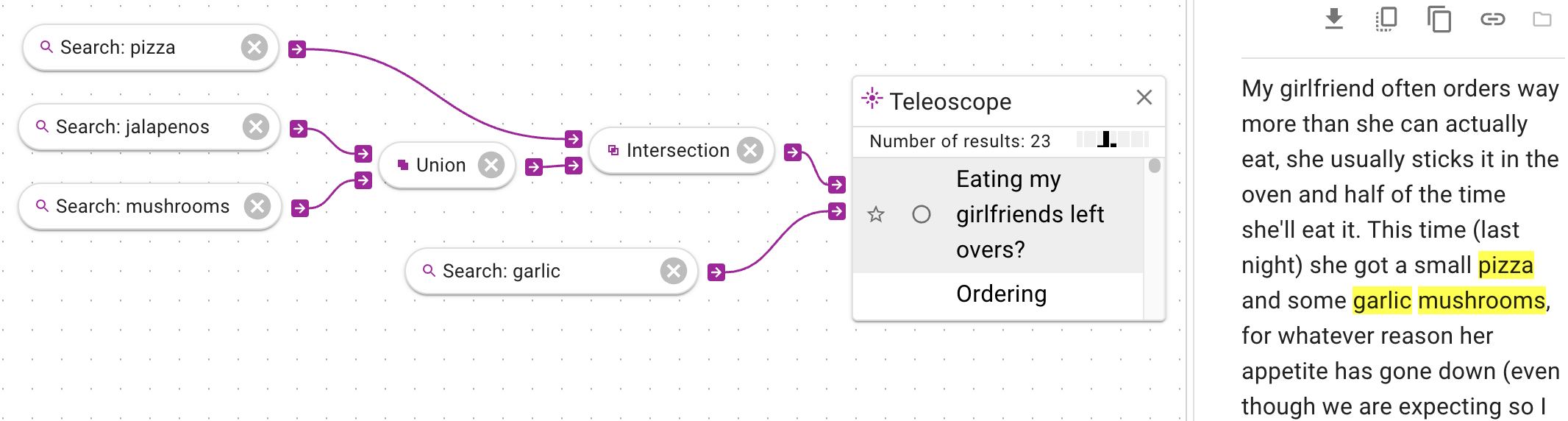
Due to the logic of Boolean operations, you could get the same result by using the same
operations in a different order. In the above, the searches are joined with union, and then the union
is interesected with the pizza search.
Unequal Weighting
 If you want to increase the influence of one source on the Teleoscope output, you can connect
multiple copies of that source. Since the source vectors are averaged, having more copies of
something allows you to weight the average.
If you want to increase the influence of one source on the Teleoscope output, you can connect
multiple copies of that source. Since the source vectors are averaged, having more copies of
something allows you to weight the average.